題目: in:裡面有兩行英文(兩行英文都有跳行、中間都沒有空白、兩行長度都不會超過9487個字母)。
舉例in內容為:
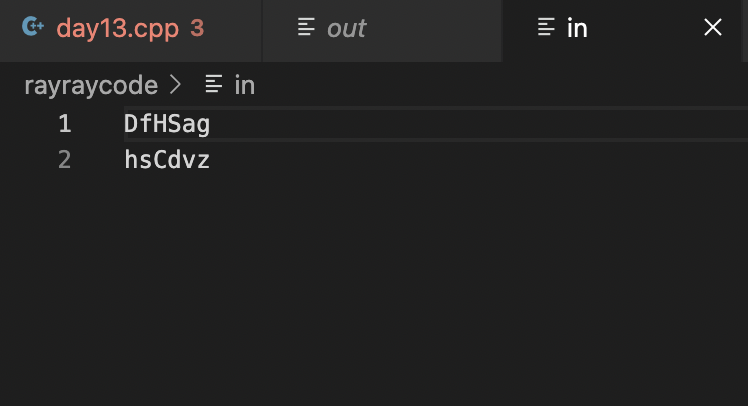
DfHSag
在out檔輸出:
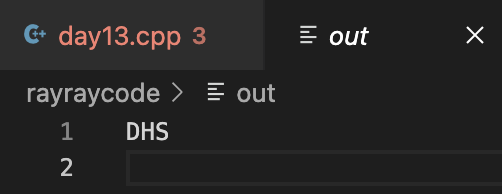
DHS
備註:若是輸出:HSD\n(沒有按照字母順序,算錯喔!)
解法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 #include<cstring> #include<fstream> #include<iostream> using namespace std; int main() { ifstream inStream; ofstream outStream; inStream.open("in"); outStream.open("out"); char str1[10000], str2[10000]; char str[10000], end[10000]; inStream >> str1;//第一行文字 for (int i = 0; i < strlen(str1); i++)//in檔第一行儲存到str1陣列中 { if(str1[i]<='z'&& str1[i]>='a')//小寫的情況 { str1[i] = str1[i] - 'a' + 'A';//轉為大寫 } } inStream >> str2;//第二行文字 for (int j = 0; j < strlen(str2);j++)//in檔第二行儲存到str2陣列中 { if(str2[j]<='z'&& str2[j]>='a')//小寫的情況 { str2[j] = str2[j] - 'a' + 'A';//轉為大寫 } } int a = 0, b = 0; for (int k = 0; k < strlen(str1); k++)//第一行長度 { for (int l = 0; l < strlen(str2);l++)//第二行長度 { start: if(str1[k]==str2[l])//字相同的情況 { str[a] = str1[k]; if(a==0) { end[b] = str[a]; b++; } for (int t = 0; t < a;t++) { if(str[a]!=str[t]) { if(t==a-1) { end[b] = str[a]; b++; } else { continue; } } else if(str[a]==str[t]) { l++; goto start; } } a++; } } } char order; for (int z = 0; z < strlen(end) - 1;z++) { for (int s = z+1; s < strlen(end);s++) { if(end[z]>end[s]) { order = end[z]; end[z] = end[s]; end[s] = order; } } } for (int c = 0; c < strlen(end); c++) { outStream << end[c]; } outStream << '\n'; inStream.close(); outStream.close(); }
解釋與詳細介紹 第二部分:主功能解析-預先設置 1 2 3 4 5 6 7 ifstream inStream; ofstream outStream; inStream.open("in"); outStream.open("out"); char str1[10000], str2[10000]; char str[10000], end[10000];
我們一開始先按照上次的技巧設定檔案,並令另外兩個文字陣列str1,str2分別代表第一行與第二行文字,str代表相同字的陣列,end代表確認字母順序的結果陣列。
1 2 inStream >> str1;//第一行文字 inStream >> str2;//第二行文字
並分別將其以inStream的方式輸入
第三部分:主功能解析-str1,str2陣列迴圈講解 1 2 3 4 5 6 7 for (int i = 0; i < strlen(str1); i++)//in檔第一行儲存到str1陣列中 { if(str1[i]<='z'&& str1[i]>='a')//小寫的情況 { str1[i] = str1[i] - 'a' + 'A';//轉為大寫 } }
再來我們看到for迴圈,兩個句子具有相同的的for迴圈,功能為將所有文字轉為大寫。我們可以看到for迴圈的條件int i = 0; i < strlen(str1); i++是將剛剛輸入inStream文字放到陣列中;而裡面下個層級的if迴圈中的str1[i]<=’z’&& str1[i]>=’a’則是代表以第i個位置(i由0~n-1,n為str1的長度,strlen(str1))去判定其大小寫情況。
若是他的ASCII Code介於’a’‘z’(97~122),則將其轉為大寫’A’‘Z’(65~90),一一對應。並在str2重複相同的動作。
第四部分:主功能解析-主要比對程式 1 2 3 4 for (int k = 0; k < strlen(str1); k++)//第一行長度 { for (int l = 0; l < strlen(str2);l++)//第二行長度 {
一開始我們先設了兩個for迴圈,並定義k與l的變數分別代表第一行(str1)和第二行(str2)長度順序。同時設立兩個變數a,b存取
1 2 3 4 5 6 7 8 9 10 11 12 13 char order;//用來暫存的變數 for (int z = 0; z < strlen(end) - 1;z++)//前一位 { for (int s = z+1; s < strlen(end);s++)//後一位 { if(end[z]>end[s])//ASCII code大小比較,前一位大於後一位 { order = end[z]; end[z] = end[s]; end[s] = order;//把兩者交換的code寫法 } } }
這裡先介紹end部分,這是我們用來確認最後答案順序的迴圈部分,我們在for迴圈部分先將z,s代表前一位和後一位的遞增變數(兩者位址僅相差”1”)而order變數則是一個暫存變數,讓我們可以方便進行兩者的直“交換”(若直接寫成end[z]=end[s]的話,無法達成交換的目的!)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 start: if(str1[k]==str2[l])//字相同的情況 { str[a] = str1[k];//另str[a]為相同字的存取位置 if(a==0) { end[b] = str[a];//將一樣的字元存進end[b] b++;//b增加 } for (int t = 0; t < a;t++)//t自0~(a-1) { if(str[a]!=str[t])//字元不相等時 { if(t==a-1)//t為前一位 { end[b] = str[a];//存入end b++; } else { continue;//繼續檢查 } } else if(str[a]==str[t]) { l++; goto start;字元相等時,跳回繼續找兩句下個同樣字 } } a++; } }
最後講解start部分,我們由第一個if迴圈中去判斷兩句的ASCII code是否相同(代表字相同),並且將他存進str[a]中,並用end[b]去判斷存取的字母順序,並利用前面提到的end部分迴圈來將其變為正確的順序。
1 2 3 4 5 for (int c = 0; c < strlen(end); c++) { outStream << end[c];//將結果寫出檔案 } outStream << '\n';//空行
最後再將結果寫出檔案就可以了!
第五部分:成果展示 in檔:
out檔:
那我們明天見~(ノ>ω<)ノ